TL;DR
What is RoboAlign-R1?
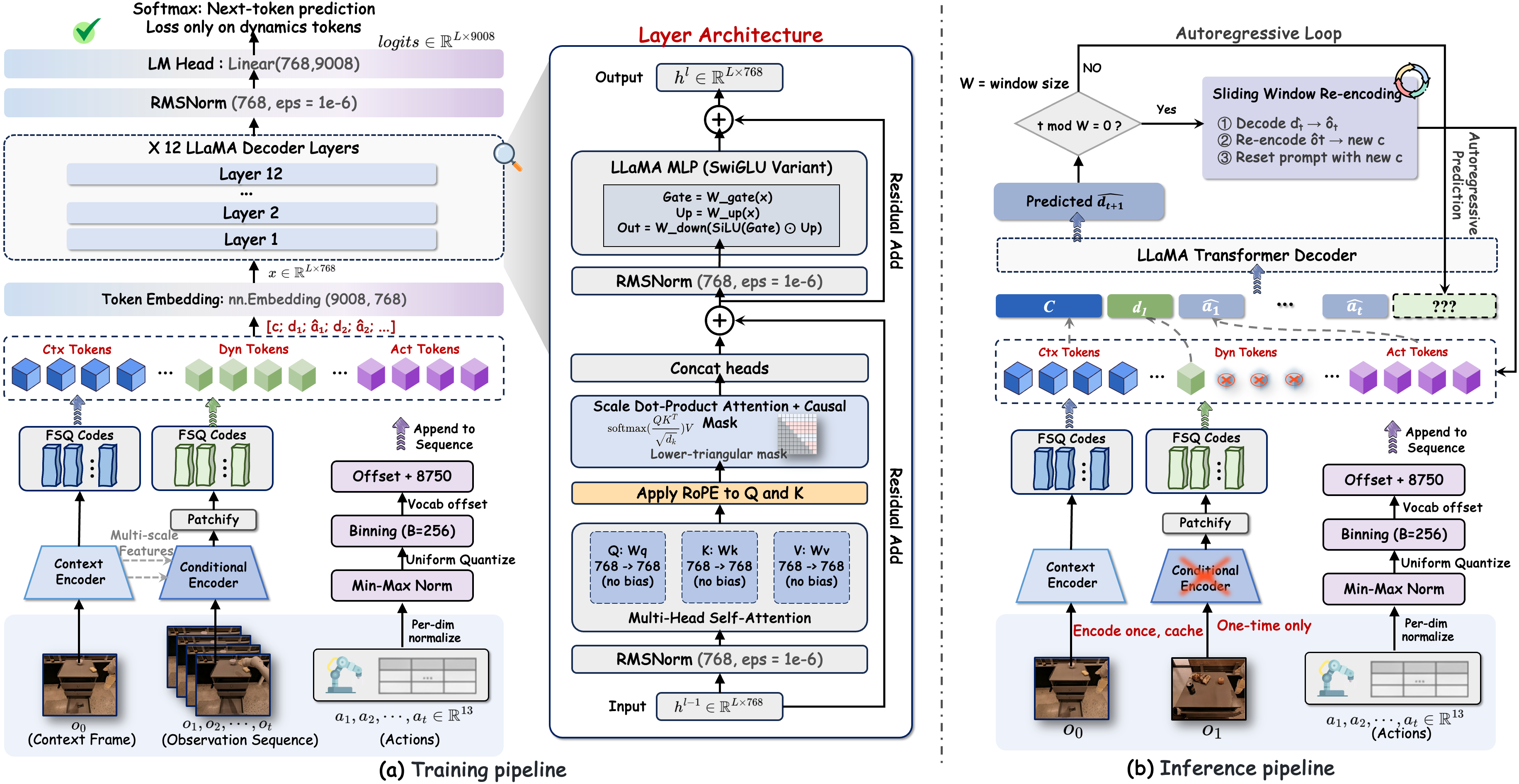
RoboAlign-R1 is a unified framework for robot video world models that replaces weak low-level RL rewards with a distilled multimodal reward, and stabilizes long-horizon autoregressive generation with a training-free Sliding Window Re-encoding (SWR) strategy.
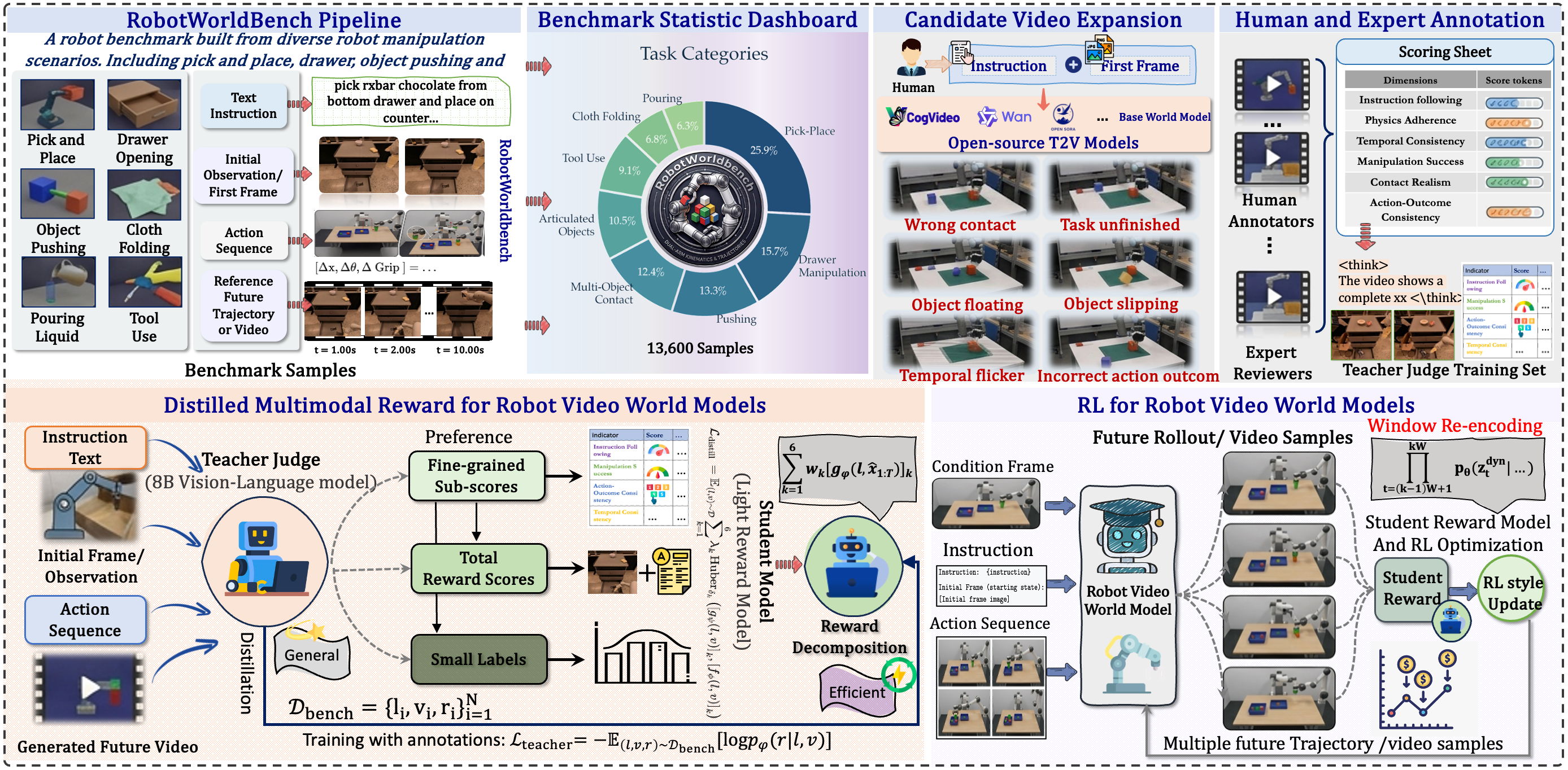
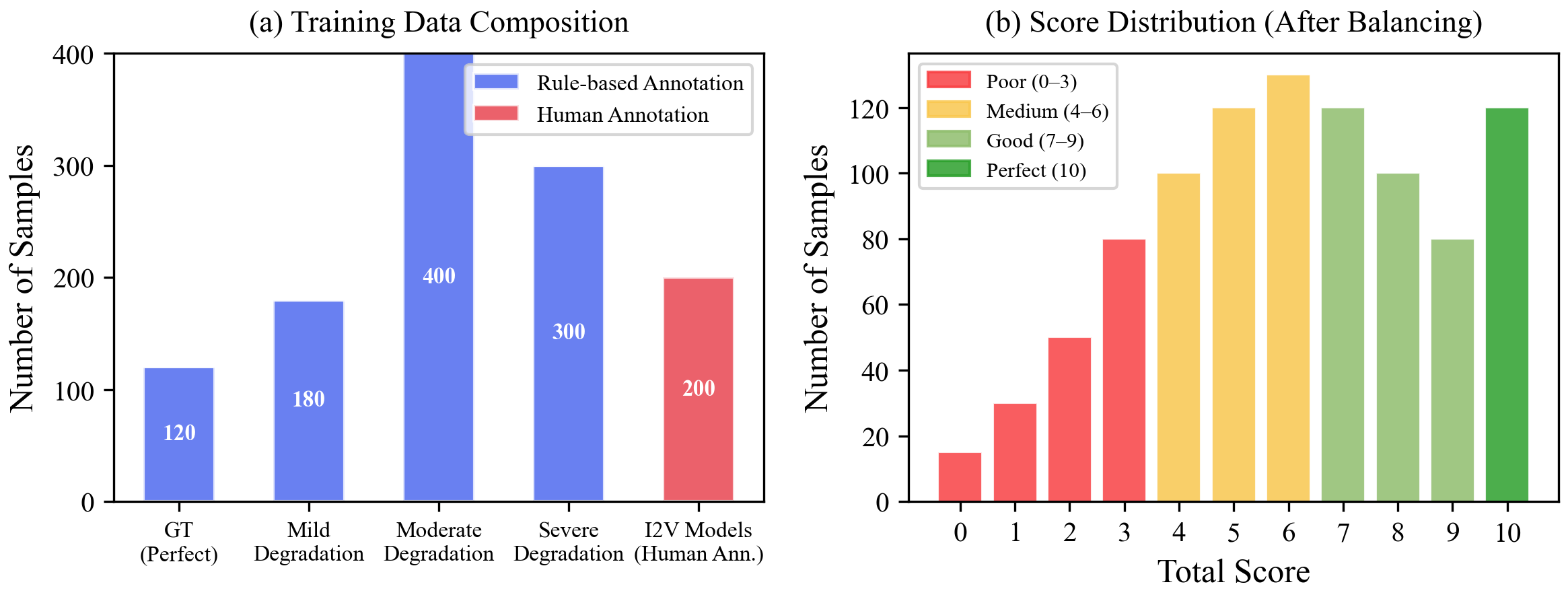
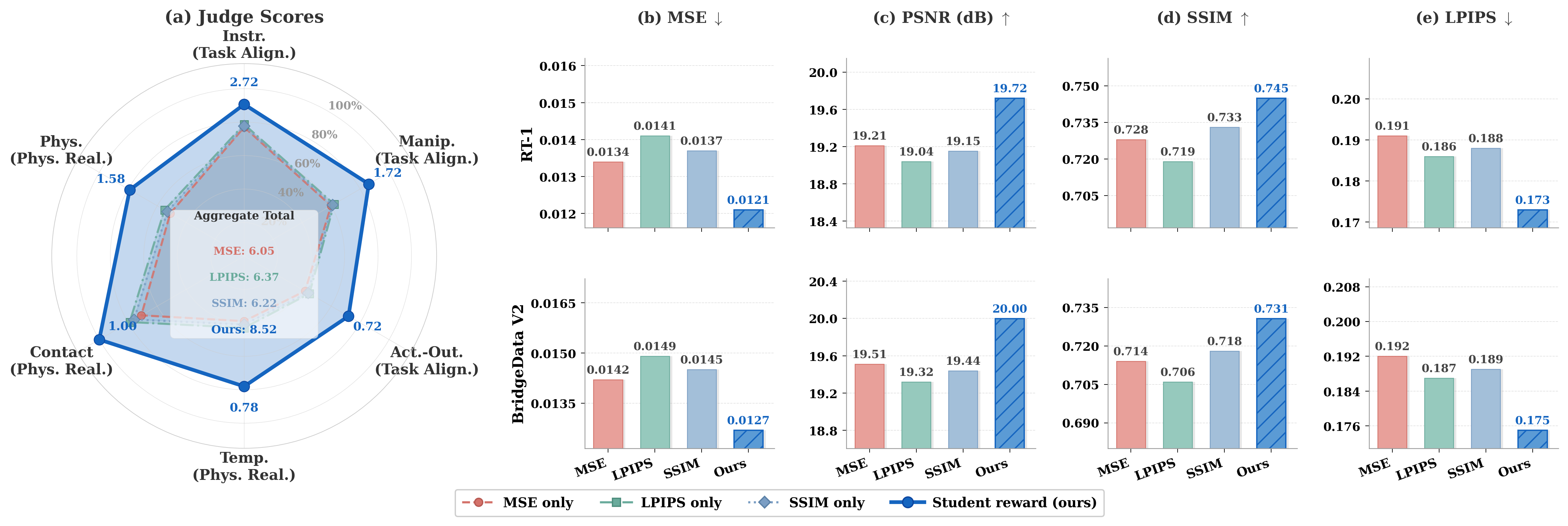
- RobotWorldBench — 10,000 annotated video–instruction pairs across 4 robot datasets, scored on 6 fine-grained dimensions.
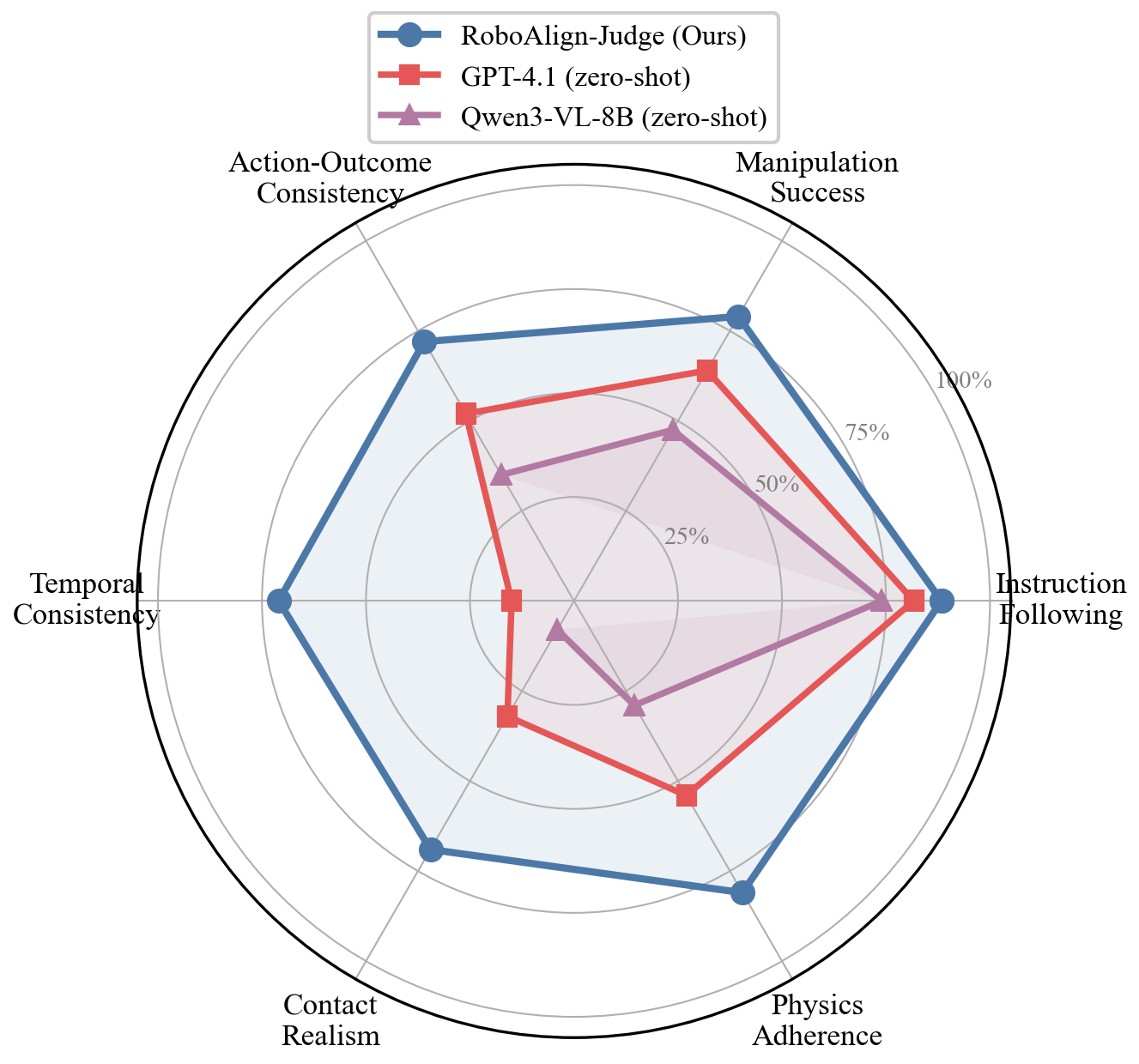
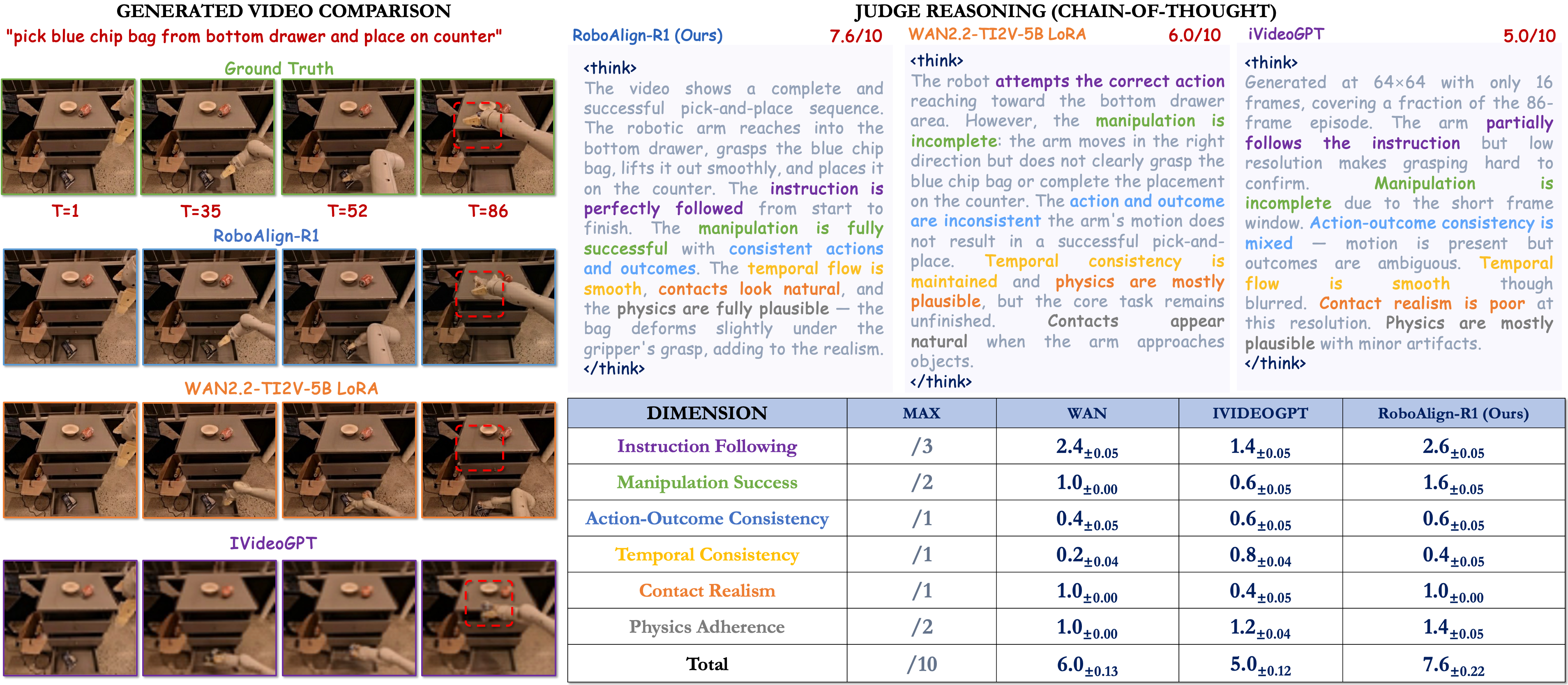
- RoboAlign-Judge (teacher) — a Qwen3-VL-8B-Thinking multimodal judge fine-tuned on RobotWorldBench.
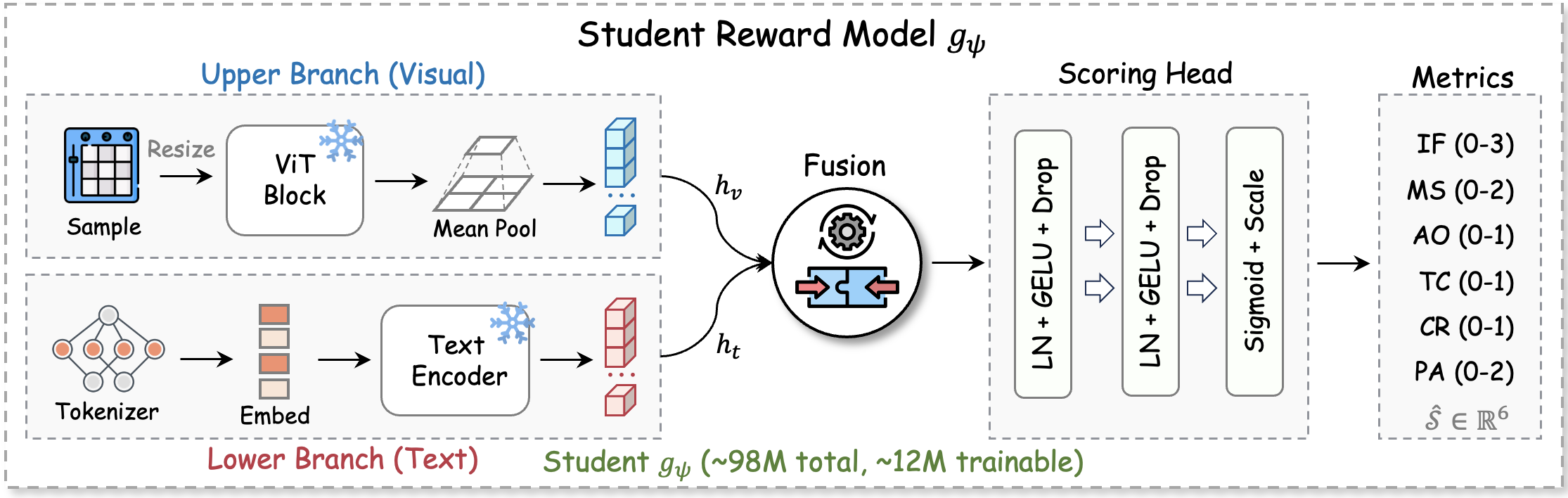
- Student Reward — a 98M compact model distilled from the teacher, running at ~50 videos/s for online RL.
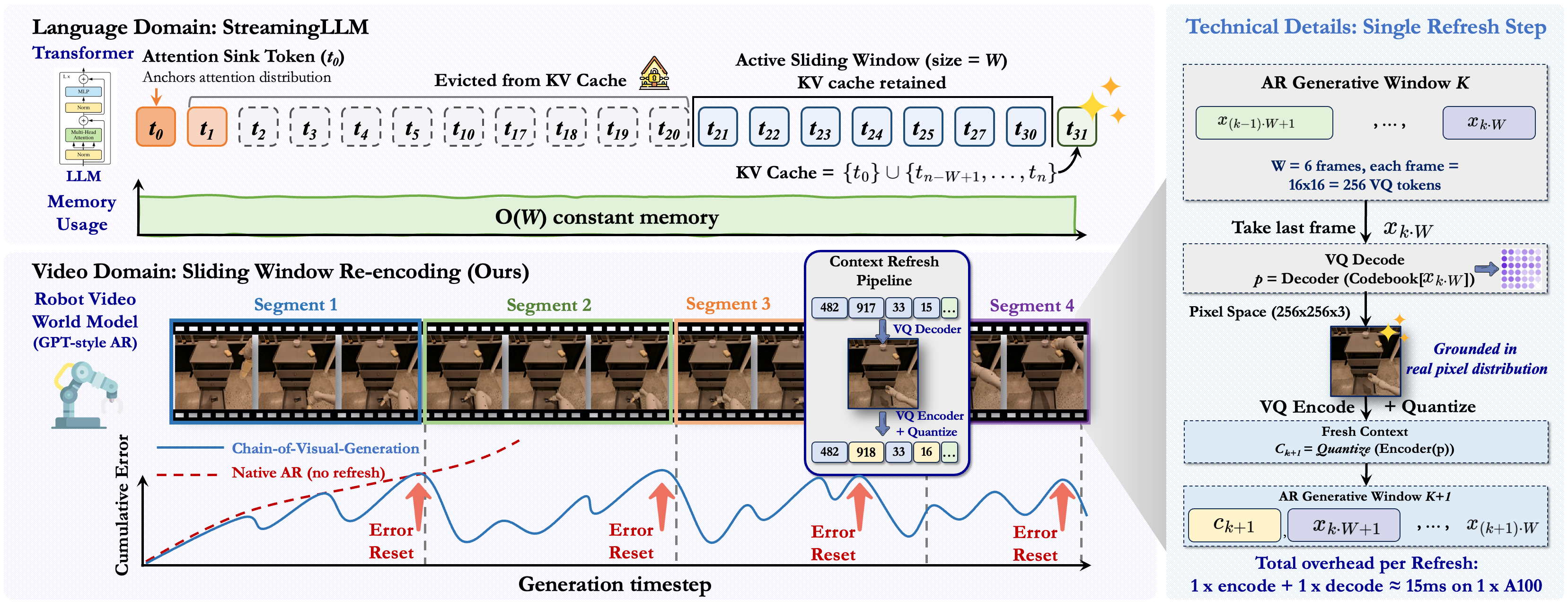
- Sliding Window Re-encoding — periodically re-encodes recent predictions into fresh context, bounding KV-cache at O(W).